
100% Code Coverage but 0% Regression Bug Protection?!
100% Code Coverage alone does not mean that we are being protected against regression bugs. That's why we need Mutation Testing.

Introduction
Many companies set code coverage targets - for example, 80% coverage, 90% code coverage, and 100% code coverage.
The problem is that even though we can have 100% code coverage, it does NOT actually mean that our tests are protecting us against regression bugs.
Starting with 0% Code Coverage
Suppose we have the following source code:
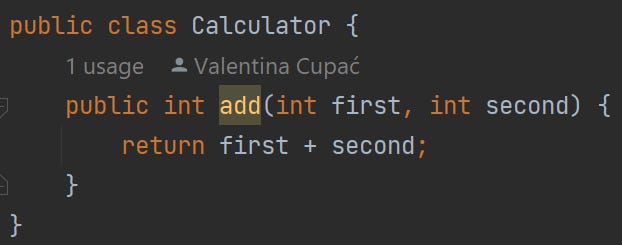
The following is our test code - it’s just an empty test method, we are not executing the add method at all:

If we run code coverage metrics, we see 0% line coverage:
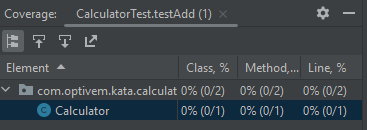
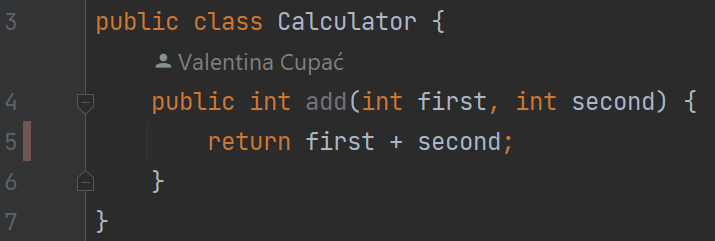
Zooming into the details, we see that the following line is not covered (marked as red on the left-hand side):
Reaching 100% Code Coverage
To reach 100% line coverage, all we need to do is to make sure that all source code lines get executed. So we call the calculator.add method:
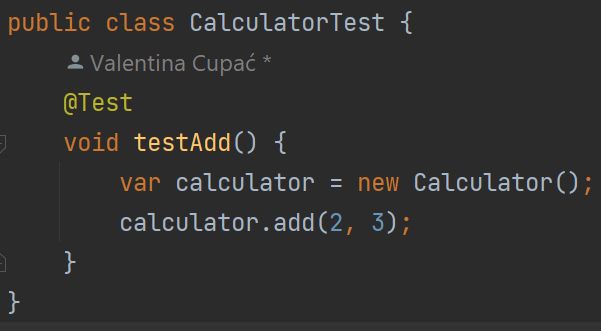
The test passes:

And we have reached 100% code coverage:

But the test isn’t protecting us!
In Step 2, we can see that we reached 100% line coverage BUT we are actually not being protected against regression bugs.
So the following is our source code (from Step 1):

The following is our unit test (from Step 2):

Let’s try to simulate introducing a regression bug into our source code. For example, one day, a developer accidentally switches from + to -:
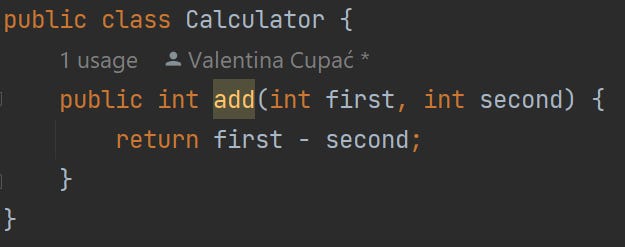
We run our tests, but the tests still pass - even though we have a regression bug!

Let’s now introduce yet another regression bug; for example, the developer accidentally deletes calculation logic and just returns 0:

We run the tests, and they still pass - even though we have a regression bug!

0% Mutation Coverage shows the reality
100% Code Coverage was giving us a false sense of security - we thought we had good tests, when we actually don’t have good tests - because the tests are not protecting us against regression bugs.
Fortunately, by running Mutation Testing (e.g. PIT Test in Java), we see the reality - 0% Mutation Coverage:

The details show that the Mutation Testing tool attempted to introduce mutants (regression bugs) and unfortunately the mutants survived (the tests were not detecting regression bugs because the tests passed even though we had regression bugs).

If you want to get started with Mutation Testing, see https://xtrem-tdd.netlify.app/Flavours/mutation-testing.
Reaching 100% Mutation Coverage
We realize we have to improve our tests - by adding the missing assertion:

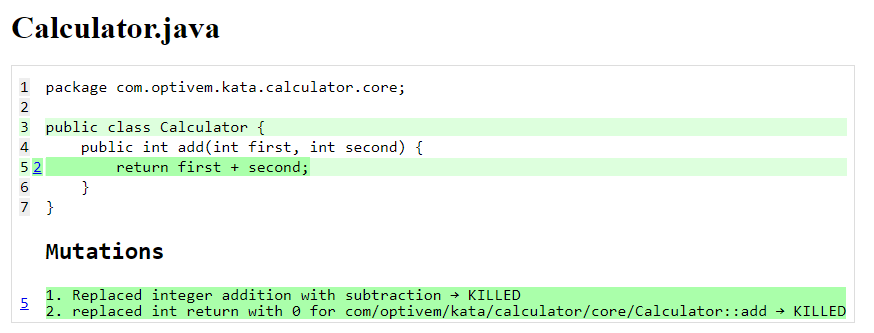
We then re-run Mutation Testing and see 100% Mutation Coverage score:

The details indicate that all mutants were killed (this means, when Mutation Testing tried to introduce regression bugs into the source code, that the tests failed, thereby detecting the regression bugs):
Summary
Code Coverage only cares about whether our source code was executed by the tests. It does not care about whether our tests are actually verifying anything. Hence, we could reach 100% Code Coverage even with zero assertions (Assertion Free Testing). Unfortunately, this kind of test suite is not protecting us against regression bugs at all - it is useless!
On the other hand, Mutation Coverage goes beyond - it actually does care about whether our tests have verifications. Hence, if we have zero assertions, we will get a 0% Mutation Coverage score, indicating to us that our test suite is not protecting us against regression bugs! Then, when we add the missing assertions, we get 100% Mutation Coverage, indicating that our tests are now protecting us against regression bugs.
For a deeper discussion about Mutation Testing, see https://journal.optivem.com/p/code-coverage-vs-mutation-testing
Isn't that a bad unit test ? it doesn't assert anything. From my understanding, it will pass on any function that accepts two parameters ?
While I agree with the idea that high coverage is a weak metric, this article still presents a straw man of testing.
The code was being written without proper test-first development. The test naming was also poor - we know it's a test, it doesn't need to be called "testX".
Before adding mutation testing, we need to use TDD correctly. This means two things:
1. Red, Green Refactor
2. Triangulation - adding multiple use cases to the tests so that the code can't work by accident
If we do those things, only writing any line of production code to satisfy tests, then we'll get 100% code coverage as a bi-product. Moreover, wherever there's NOT coverage, we most likely have an unexpected bug in our code or tests.
That said, mutation testing can prove other stuff. I'm yet to find a good tool for doing it at scale.