
TDD in Legacy Code - Commit Stage
In Legacy Code, developers might be manually building the system. It would be useless to practice TDD with manual builds. Let's see how to introduce Build Automation.

🔒Hello, this is Valentina with a premium issue of the Optivem Journal. I help Engineering Leaders & Senior Software Developers apply TDD in Legacy Code. This article is part of the TDD in Legacy Code series. To get these articles in your inbox every week, subscribe:
Legacy Code: the build is (often) broken
The developer was manually compiling the code (perhaps running a few tests, if any). It seemed to be working, so they deployed it to a server.
A few minutes later, a teammate pulled the latest source code, ran compilation (and very few tests, if any), and said the build didn’t work.
The first developer then exclaimed:
“But it works on my machine!“
In Legacy Code projects, there might not be any centralized Build Server, and the build process might be manual. The development team might compile the code locally and produce artifacts that they would later use for manual deployment.
TDD is ineffective if you have Manual Builds
The problem is, that when the build process is manual, it is error-prone and time-consuming. Furthermore, the person who manually builds the system might not even be running any tests, if any. We have the problem of “it works on my machine”, whereby the tests (if any) might be passing on that machine but not generally working.
Therefore, even if a team tried to do TDD, their tests could be all green locally on their machine, but those same tests could fail on other machines, and the software itself might not be working. Furthermore, the developer who manually builds the system might forget to run the tests and just compile the code.
Consequently, if you try to practice TDD but you have Manual Builds, then TDD is only partially effective for you.
We need Build Automation for effective TDD
That’s why we need to automate the build process - using the Commit Stage. This ensures that code compilation and test execution are done on a separate independent machine. This prevents the case that compilation and tests “work on my machine“, and thus prevents faulty builds.
We automated the build using the Commit Stage. The Commit Stage is the first stage in the Pipeline—it compiles code, runs developer-facing technically focused tests, and runs static code analysis. Assuming all that passed, the Commit Stage generates Artifacts and stores them in the Artifact Repository. Legacy Projects may not have a Commit Stage at all, or they might be poorly designed, so that’s what we have to fix to enable the execution of technical tests.
Furthermore, having a Commit Stage within the Pipeline is a prerequisite for Continuous Integration (CI), irrespective of TDD.
Therefore, in Legacy Projects, don’t jump to TDD unless you have setup Build Automation first. That’s why, in the TDD in Legacy Code Transformation, we start with the Pipeline Commit Stage:
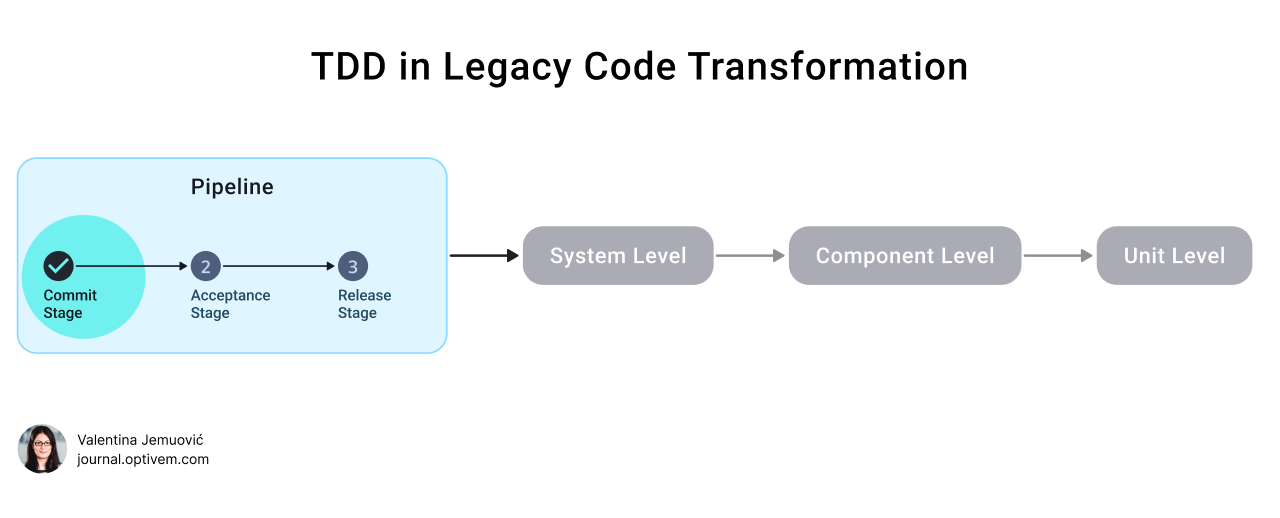
Here are the steps for adding the Commit Stage to Legacy Code. You’ll get tasks to implement in your GitHub Sandbox Project. ⬇️⬇️⬇️